728x90

아주 긴 SQL 쿼리를 오피셜하게 정렬하는 방식은 가독성과 유지보수성을 최대화하는 것이 핵심입니다. Oracle SQL 기준으로, 다음의 규칙과 예제를 참고하세요.
1. 일반적인 SQL 정렬 규칙
- SQL 예약어: 모두 대문자로 사용 (SELECT, FROM, WHERE 등).
- 컬럼 및 테이블 이름: 소문자 또는 케이스 일관성 유지.
- 들여쓰기:
- 예약어 다음에 한 탭 또는 2~4개의 공백으로 들여쓰기.
- 서브쿼리는 블록으로 들여쓰기.
- 각 절을 새로운 줄에 작성:
- SELECT, FROM, WHERE, GROUP BY, ORDER BY 등은 각 줄에 배치.
- 여러 컬럼 선택 시: 각 컬럼을 별도의 줄에 작성.
- JOIN:
- JOIN 절은 FROM 절 아래 들여쓰기.
- ON 조건은 새로운 줄로 작성.
- WHERE 절:
- 논리 연산자(AND, OR)는 새로운 줄에서 정렬.
- 주석 추가: 복잡한 쿼리는 설명을 추가하여 의도를 명확히 작성.
4. SQL 코드 정렬 도구
긴 쿼리를 수동으로 정렬하기 어렵다면 아래와 같은 도구를 사용하는 것도 추천합니다.
- SQL Formatter Online (https://www.sqlformat.org/)
- PL/SQL Developer: SQL 정렬 기능 제공.
- SQLcl (Oracle SQL Command Line):
SQL 문장을 자동으로 정렬합니다.SET SQLFORMAT ANSICONSOLE
5. Best Practice 정리
- Consistency: 동일한 규칙으로 모든 SQL 작성.
- Documentation: 복잡한 로직에는 반드시 주석 작성.
- Automation: 도구를 활용해 정렬 시간을 단축.
이 방식으로 SQL 쿼리를 작성하면 팀 협업과 유지보수가 훨씬 쉬워질 것입니다.
728x90
2. 예제: 긴 쿼리 정렬
SELECT
emp.employee_id,
emp.first_name,
emp.last_name,
emp.department_id,
dept.department_name,
CASE
WHEN emp.salary > 5000 THEN 'HIGH'
ELSE 'LOW'
END AS salary_level
FROM
employees emp
JOIN
departments dept
ON emp.department_id = dept.department_id
WHERE
emp.hire_date >= TO_DATE('2020-01-01', 'YYYY-MM-DD')
AND emp.status = 'ACTIVE'
AND (
emp.department_id IN (10, 20, 30)
OR emp.manager_id IS NOT NULL
)
GROUP BY
emp.employee_id,
emp.first_name,
emp.last_name,
emp.department_id,
dept.department_name
HAVING
COUNT(emp.employee_id) > 1
ORDER BY
emp.department_id ASC,
emp.last_name ASC;
3. 서브쿼리 포함 예제
SELECT
emp.employee_id,
emp.first_name,
emp.last_name,
(
SELECT
AVG(salary)
FROM
employees
WHERE
department_id = emp.department_id
) AS avg_department_salary
FROM
employees emp
WHERE
emp.status = 'ACTIVE'
AND emp.salary > (
SELECT
AVG(salary)
FROM
employees
WHERE
hire_date >= TO_DATE('2015-01-01', 'YYYY-MM-DD')
)
ORDER BY
emp.salary DESC;
728x90
질문 : ,(코머) 를 아래 앞으로 표기하는 방식도 있던데
네, SQL에서 콤마(,)를 아래로 내리는 방식은 가독성을 높이기 위한 또 다른 스타일입니다. 이 스타일은 특히 **열(Column)**이나 **값(Value)**이 많을 때, 각 항목의 추가/삭제 시 변경 이력을 명확히 하고 충돌을 줄이는 데 유리합니다.
1. 콤마를 아래로 표기하는 방식
콤마를 항목의 앞부분에 위치시키는 방식으로, 아래와 같은 이점이 있습니다:
- 새 항목을 추가하거나 삭제할 때 마지막 항목을 특별히 다룰 필요가 없음.
- 버전 관리 도구(Git 등)에서 변경 내역(diff)을 더 깔끔하게 확인 가능.
- 각 항목이 독립적으로 보이기 때문에 실수를 줄임.
2. 예제: SELECT 절에서의 콤마 내림
SELECT
emp.employee_id
, emp.first_name
, emp.last_name
, emp.department_id
, dept.department_name
, CASE
WHEN emp.salary > 5000 THEN 'HIGH'
ELSE 'LOW'
END AS salary_level
FROM
employees emp
JOIN departments dept
ON emp.department_id = dept.department_id
WHERE
emp.hire_date >= TO_DATE('2020-01-01', 'YYYY-MM-DD')
AND emp.status = 'ACTIVE'
AND (
emp.department_id IN (10, 20, 30)
OR emp.manager_id IS NOT NULL
)
GROUP BY
emp.employee_id
, emp.first_name
, emp.last_name
, emp.department_id
, dept.department_name
HAVING
COUNT(emp.employee_id) > 1
ORDER BY
emp.department_id ASC
, emp.last_name ASC;
3. INSERT INTO에서의 활용
INSERT INTO employees (
employee_id
, first_name
, last_name
, department_id
, hire_date
, salary
)
VALUES (
101
, 'John'
, 'Doe'
, 10
, TO_DATE('2024-01-01', 'YYYY-MM-DD')
, 6000
);
4. 장단점 비교
| 장점 | 단점 |
| 항목 추가/삭제 시 코드 변경이 간단함 | 처음 사용하는 개발자가 낯설게 느낄 수 있음 |
| 버전 관리에서 충돌(diff) 최소화 가능 | 기존의 코드 스타일과 충돌할 수 있음 |
| 가독성 향상: 각 항목이 독립적으로 보임 | 일부 SQL 도구에서 자동 포맷팅에 미지원 |
| 구조적이며 논리적으로 정돈된 코드 제공 | 팀 규칙으로 정하지 않으면 혼란 초래 가능 |
5. 도입 시 유의점
- 팀 합의: 모든 팀원이 동일한 스타일을 사용하도록 가이드라인을 정해야 합니다.
- 자동 포매터 설정: SQL 포맷팅 도구에서 콤마 내림 스타일을 지원하는지 확인하고, 해당 설정을 적용합니다.
- 예: SQL Formatter Online이나 IDE(예: IntelliJ, DataGrip)의 커스텀 룰.
6. 도구와 관련 설정
일부 SQL 도구는 콤마 위치를 선택할 수 있도록 옵션을 제공합니다. 예를 들어:
- DataGrip:
- File > Settings > Code Style > SQL로 이동.
- Wrapping and Braces에서 콤마 위치 설정 가능.
이 방식은 대규모 프로젝트에서 변경 관리 및 협업 시 특히 유용합니다. 팀의 코드 스타일 가이드라인에 맞추어 적용을 고려하세요!
필자가 고안한 '하노이 탑' 방식 쿼리 정렬법
1. 주요 개념 : 단어의 성격으로 좌우를 분리 (동사와 동사의 목적어, 전치사와 전치사의 목적어)
2. 각 라인간 정렬은 이 둘의 경계를 한 선을 기준으로 위아래로 연장해서 가운데 정렬 (마치 하노이 탑을 연상하게 끔함)
3. 서브 쿼리 블럭은 아예 통째로 오른쪽 블럭에 몰아 넣어 메인 쿼리와의 명확한 분리
4. 물론, 너무나 당연한 얘기겠지만 편집기 폰트는 반드시 고정폭 폰트로 해야
SELECT emp.employee_id
, emp.first_name
, emp.last_name
, (
SELECT AVG(salary)
FROM employees
WHERE department_id = emp.department_id
) AS avg_department_salary
FROM employees emp
WHERE emp.status = 'ACTIVE'
AND emp.salary > (
SELECT AVG(salary)
FROM employees
WHERE hire_date >= TO_DATE('2015-01-01', 'YYYY-MM-DD')
)
ORDER BY emp.salary DESC;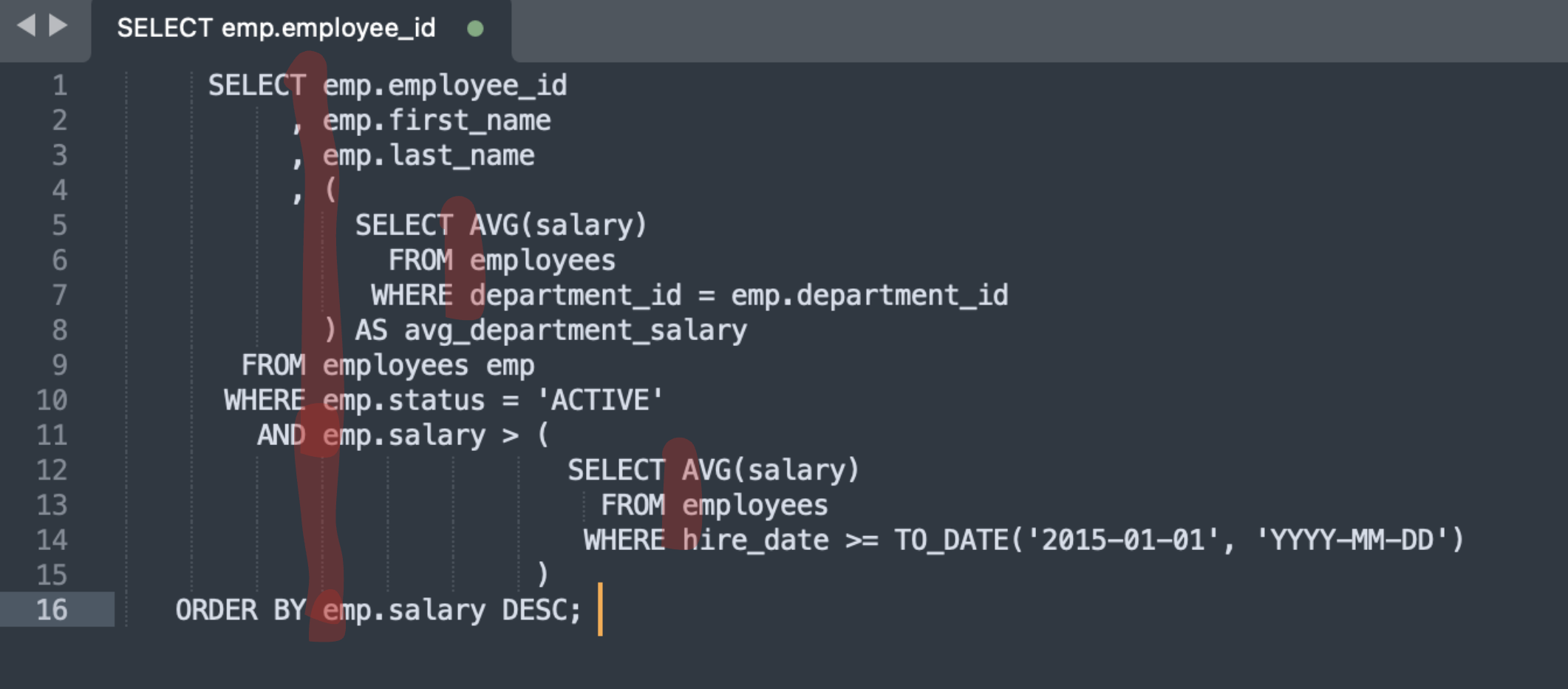
728x90
'Oracle Database 강좌' 카테고리의 다른 글
| 테이블과 프로시져 혹은 함수과의 관계를 표현하는 레이아웃 (0) | 2024.11.26 |
|---|---|
| APEX AI Assistant: 차세대 AI 어시스턴트의 가능성과 미래 (0) | 2024.11.26 |
| SQL Fiddle: 웹에서 편리하게 SQL 쿼리를 연습하고 테스트하는 방법 (0) | 2024.11.26 |
| Oracle의 스토어 프로시저를 주석을 제외한 순수 소스 코드로 확인하려면 (0) | 2024.11.24 |
| 오라클 데이터베이스를 배워보자 (0) | 2024.10.06 |